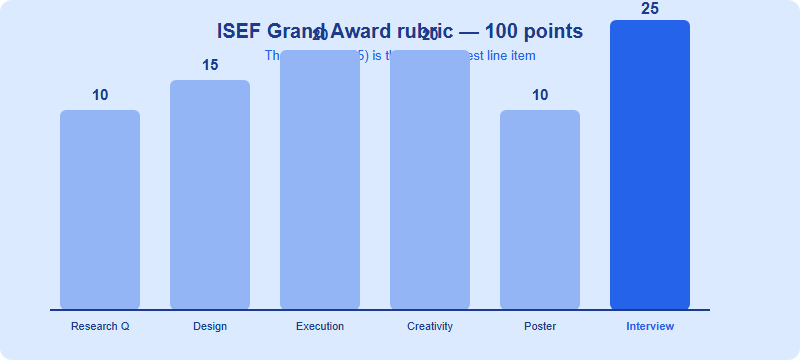
At the Regeneron ISEF booth, judges are not grading your topic — they are grading you explaining it. On the official 100-point Grand Award rubric (per societyforscience.org), the interview is worth 25 points on its own, the single largest line item, and your answers also shape the Creativity (20) and Execution (20) scores. Judges probe how deeply you understand your own work, your scientific reasoning, your experimental rigour, and how you handle hard questions. This guide decodes exactly what they assess and how to prepare.
How the 100-point rubric actually weights the interview
Many finalists over-invest in a beautiful poster and under-prepare for the 15-minute conversation. That is backwards. The official Grand Award judging criteria (societyforscience.org/isef/grand-award/criteria/) splits Presentation into two parts: the poster is worth 10 points, and the interview is worth 25. Combined, Presentation is 35 of 100 — more than Execution (20) or Creativity (20). And because judges form their view of your creativity and rigour partly during the conversation, the interview effectively influences far more than 25 points.
Here is the full breakdown, taken directly from the official rubric. The science and engineering rubrics differ only in wording for the first three sections; the Creativity and Presentation weights are identical.
| Section | Science wording | Engineering wording | Points |
|---|---|---|---|
| I | Research Question | Research Problem | 10 |
| II | Design & Methodology | Design & Methodology | 15 |
| III | Execution: Data Collection, Analysis & Interpretation | Execution: Construction & Testing | 20 |
| IV | Creativity & Potential Impact | Creativity & Potential Impact | 20 |
| V | Presentation — Poster 10 + Interview 25 | Presentation — Poster 10 + Interview 25 | 35 |
| Total | 100 | ||
Two operational facts matter here. First, per the official FAQ, each entry is judged at least four times — so you will repeat your explanation to multiple judges, each holding a Ph.D./equivalent or six-plus years of relevant experience. Second, judging runs in 15-minute interview periods, and judges later caucus to decide category winners. You are not delivering one perfect monologue; you are having several short, high-stakes scientific conversations with experts who will compare notes.
The four things judges are really listening for
The official rubric lists the interview sub-criteria explicitly. Judges look for “clear responses, understanding of basic science, understanding [of] interpretation and limitations, degree of independence, recognition of potential impact, quality of further research ideas, [and] team contributions.” Strip that down and four themes drive most of the score.
1. Depth of understanding of your own work. Judges can tell within two questions whether you ran the project or merely stood next to it. They ask “why this method and not another?” and “what would happen if you changed this variable?” There is a reason for this: the rubric instructs judges to assess your degree of independence, and the official guidance says that for projects done at home, in a school lab, or at a research facility, the judge should determine how much mentoring or professional guidance you received (documented on the relevant approval forms). You cannot fake ownership of work you did not do.
2. Scientific reasoning. It is not enough to state results; you must reason from evidence. Strong finalists explain why a result follows from the data, connect their findings to existing literature, and reason out loud about mechanism. Judges reward students who say “the data support X, but only under condition Y” over students who overclaim.
3. Experimental rigour and limitations. The rubric explicitly rewards “understanding interpretation and limitations.” Counter-intuitively, naming the weaknesses of your own study scores points. Saying “my sample size was small, so I treat this as a pilot result and here is how I would power a follow-up” demonstrates exactly the maturity judges with doctoral training want to see.
4. Handling hard questions. Judges deliberately push into uncertainty. The point is not to trap you — it is to see how you think when you do not know. The best answer to a question you cannot answer is honest reasoning: “I did not test that directly, but based on my results I would predict Z, and here is how I would check it.” That single move feeds two sub-criteria at once: scientific reasoning and “quality of further research ideas.”
Note the rule that protects multi-year researchers: if your project is a multi-year effort, the interview should focus only on the current year’s work. Prepare to draw a crisp line around what is new this year — judges are instructed not to credit prior years’ progress.

A practical preparation plan for the booth
Preparation is not memorising a script — judges can hear a memorised pitch, and it reads as low independence. The goal is fluency: knowing your project so well that you can answer any of four judges’ unscripted questions in plain English. The table maps each interview sub-criterion to a concrete rehearsal action.
| Interview sub-criterion (official) | What judges probe | How to rehearse |
|---|---|---|
| Clear responses | Can you explain your project in 90 seconds, then in detail? | Practise a layered pitch: 30-second hook, 2-minute core, deep-dive on demand. |
| Understanding of basic science | Do you grasp the fundamentals your project rests on? | Be ready to define every term and mechanism on your board from first principles. |
| Interpretation & limitations | Do you know what your data can and cannot say? | Write your three biggest limitations on a card; rehearse stating each unprompted. |
| Degree of independence | Did you do the work and the thinking? | Be able to justify every method choice as yours; disclose mentoring honestly. |
| Potential impact & further research | Why does this matter, and what is next? | Prepare one impact sentence and two concrete next experiments. |
| Team contributions (if applicable) | Did every member contribute and understand the work? | Each teammate rehearses the whole project, not just their slice. |
Three rehearsal tactics consistently separate confident finalists from nervous ones:
- Run mock interviews with a hostile clock. Time yourself to 15 minutes, and have someone with real subject knowledge interrupt you with “why?” and “what if?” repeatedly. The discomfort is the training.
- Defend every choice on your poster. For each figure, control, and statistic, be able to answer “why is this here?” If you cannot, either learn it or remove it.
- Practise the honest non-answer. Rehearse saying “I do not have data on that, but I would predict… and test it by…” until it is reflexive. This is the highest-leverage sentence in the entire interview.
If you are still upstream of the booth — choosing a topic or working out your route to the finals — start there first: see our guides on how to choose an ISEF research topic and every path to the ISEF finals. The interview rewards depth that begins with the right question, and a topic you genuinely chose is far easier to defend than one handed to you.
Where coaching helps — and where it must stop
The booth interview is the clearest reason a “prep shop” cannot manufacture an ISEF result. A ghost-written or outsourced project collapses the moment a Ph.D. judge asks why you chose a particular control — because the rubric is explicitly designed to measure your independence. This is the dividing line in research coaching: the value is in helping a student do real, rigorous work and then articulate it clearly, never in doing the work for them.
That is the philosophy Embark operates on — a research school, not a prep shop. Embark is the international competition team of Youfang Education, founded in 2016, and its model pairs students with discipline-matched mentors (Embark reports a network of 3,000-plus contracted mentors and a record spanning all 22 ISEF categories, per Embark). For interview preparation specifically, mentoring works by making the student’s understanding genuinely deeper: a domain mentor runs mock interviews, presses on methodology and limitations, and rehearses the honest reasoning that judges reward — while the experiments, analysis, and answers remain the student’s own. Coaching that respects that boundary is also the only kind that survives four independent judges and a caucus. For more on what judges weigh across the whole project, see our companion piece on what ISEF judges look for at the booth.
Frequently asked questions
How much is the ISEF interview worth?
On the official 100-point Grand Award rubric, the interview is worth 25 points and the poster 10 — together Presentation is 35, the largest section (societyforscience.org).
How long is each ISEF judging interview?
Judging is organised in 15-minute interview periods, and per the official FAQ each entry is judged at least four times by different Grand Award judges.
What is the best way to answer a question I do not know?
Reason from your data toward a testable prediction — “I did not test that, but I would expect… and check it by…” Honest reasoning scores; bluffing does not.
Do judges only ask about this year’s work?
Yes for multi-year projects — official guidance says the interview should focus only on the current year’s work, so be ready to define what is new.
Work with Embark
Turn a real question you care about into an ISEF-caliber project — and learn to defend it at the booth — with discipline-matched mentors who coach the work, never do it for you.
Embark is an independent research-coaching organization, the international competition team of Youfang Education; it is NOT affiliated with, endorsed by, or sponsored by the Society for Science or Regeneron ISEF. Any results cited reflect Embark's own published record (per Embark). Always confirm current details on societyforscience.org. Confirmed errors corrected within 7 working days.